Multilingual Named Entity Extractor
This is a simple Flask web application that extracts named entities from medieval texts. It is based on the Flair algorithm trained on 7.6k hand-annotated documents (2.3M tokens) and specific stacked embeddings (static + contextual).
The application is able to extract the following entities: PERSONS and LOCATIONS in a single or nested-mode and in a Multilingual environment (Trained for historical Latin, French and Spanish) starting from a raw text or raw text file.
The datasets and models supporting this app can be downloaded from our Zenodo repository . As well as the paper introducing the annotated datasets and several NLP architecture benchmarks can be consulted at here
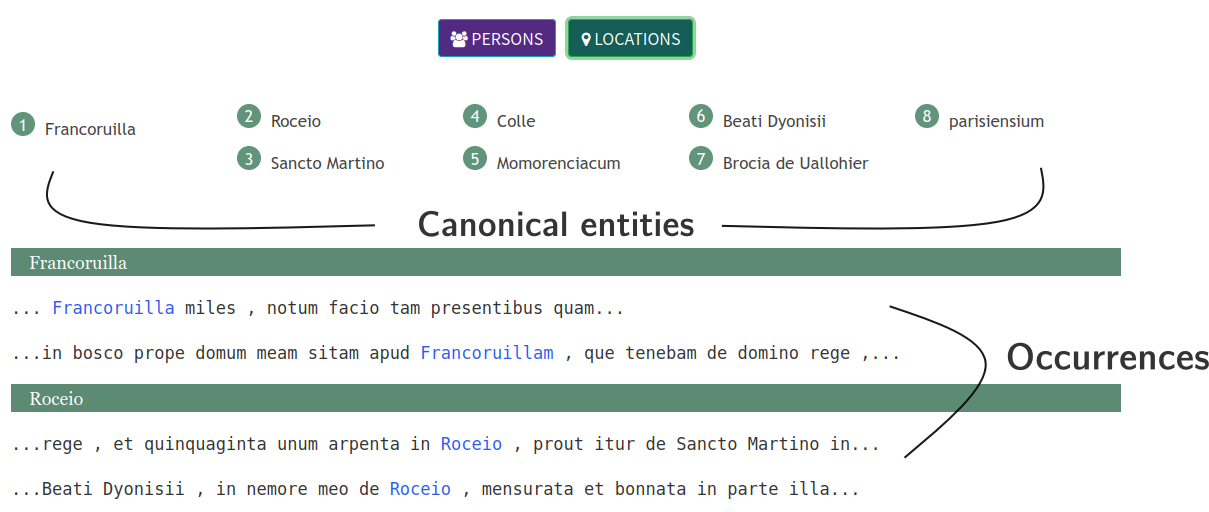
The inferences from the NER model are displayed into 6 tabs:
Display an HTML view of the model inference using a color code. The overlapping entities (normally a locative used as patronym) will appear encapsulated.
In the example "Francovilla" is recognized as a locative patronym, while "Guillelmus Bateste" as a complex name (also called by-name).

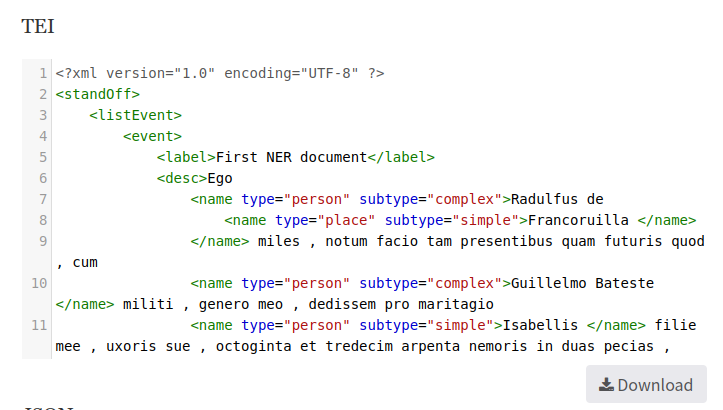
Display a valid TEI and json annotated version.
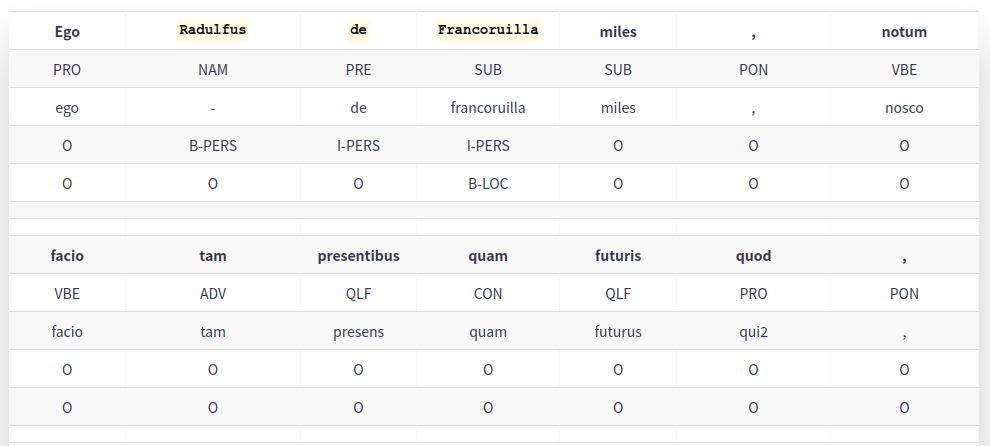
Display a linguistic-features annotated version with POS, Lemma and entities.
POS and Lemma were obtained using the Omnia lemmatizer.
Display a TSV downloadable version with POS, lemma and entities

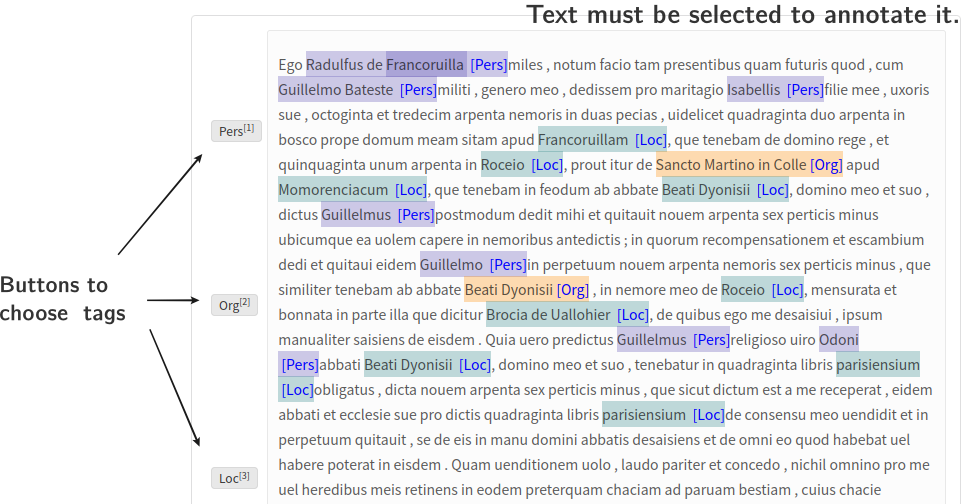
Display an annotation interface to correcting model hypothesis. Annotation can be downloaded in a BIO-format txt file.
In the example some ORG entities (not covered by the present NER model) can be added to the hypothesis
Propose a grouping of PERS and LOC entities based on his sequence-character similarity.